漫剧全自动字幕首帧烧录 Skill:Codex 5.5/DeepSeek V4/Gemini 3 混战
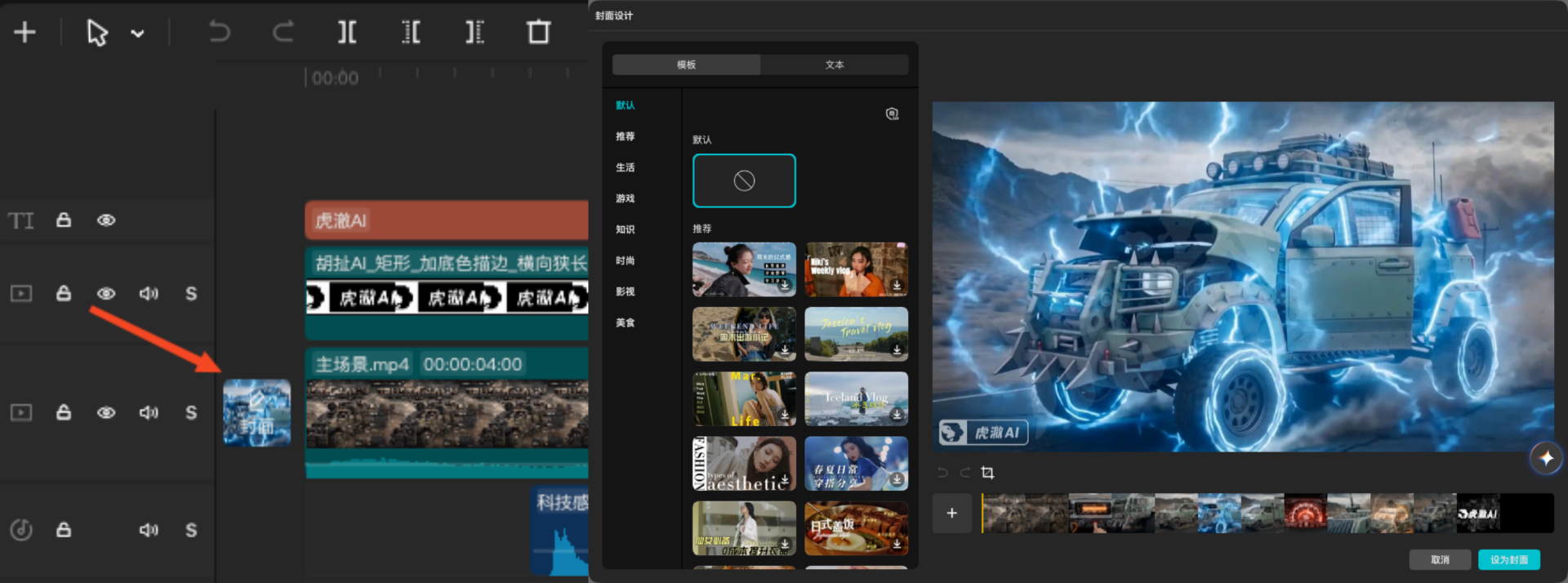
上一篇 漫剧全自动字幕翻译 Skill:Codex 5.5/DeepSeek V4/Gemini 3 混战 中,曾老师介绍了使用三个大模型工具进行字幕翻译和检验的流程。
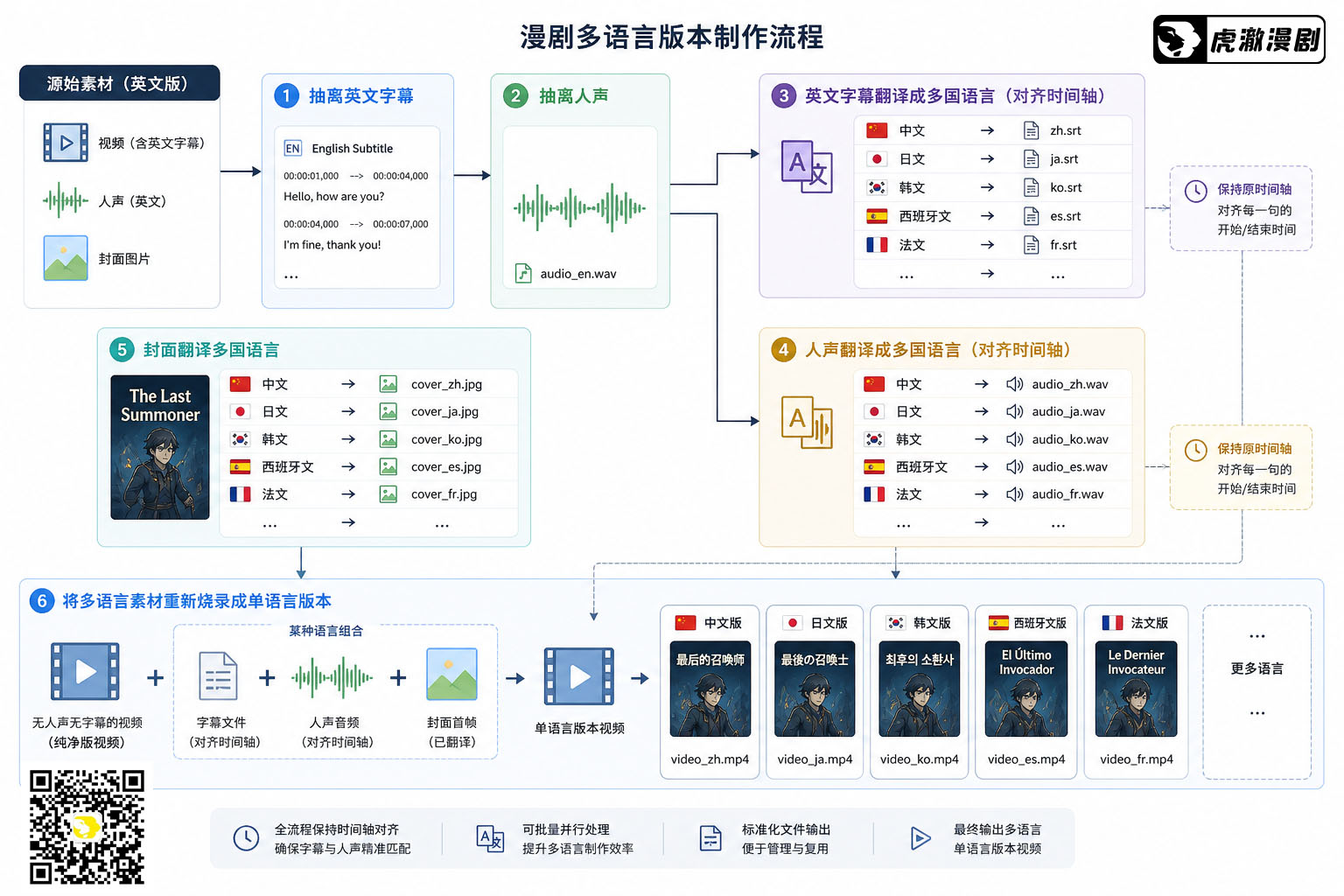
本篇接着介绍利用大模型 + ffmpeg 进行多语言字幕和首帧烧录流程。
任务流程回顾
建议回顾一下上篇中的字幕与首帧烧录全流程。下面是流程图,文字版见上篇。
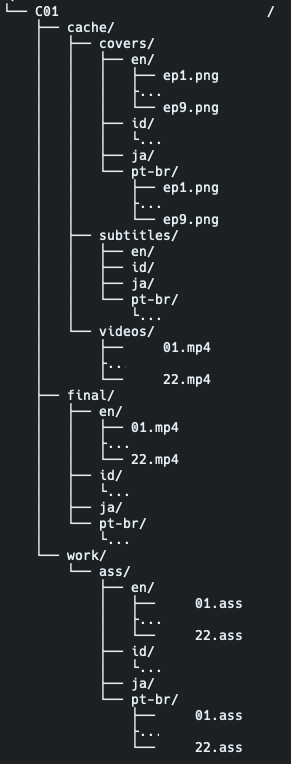
任务文件夹结构
无论是自动化程序还是 AI(或者正经人类程序员),都会先将过程结构化以方便推导。下面是整个执行过程中的文件夹结构:
1└── C01
2 ├── cache //过程中使用的中间素材
3 │ ├── covers //多国语言封面首帧图片
4 │ │ ├── en
5 │ │ ├── id
6 │ │ ├── ja
7 │ │ └── pt-br
8 │ ├── subtitles //多国语言 SRT 字幕
9 │ │ ├── en
10 │ │ ├── id
11 │ │ ├── ja
12 │ │ └── pt-br
13 │ └── videos //无字幕原视频
14 ├── final //最终生成的多国语言封面 + 视频
15 │ ├── en
16 │ ├── id
17 │ ├── ja
18 │ └── pt-br
19 └── work //过程中生成的中间素材
20 └── ass //将 SRT 转换成 ASS,以控制字体、字号、边框、位置
21 ├── en
22 ├── id
23 ├── ja
24 └── pt-br
由于完成后的文件数量众多(数百个文件)无法一一展示,我提供一下简化的文件夹结构截图。从图中可以看出,工作完成后,只需要将 final 文件夹打包就可以得到四国语言的最终视频了。
烧录首帧的必要性
下图是在剪映软件中为视频加入首帧的操作流程。
大多数视频平台在没有提供明确的封面图的前提下,都会自动将视频的首帧作为封面图截取。如果我们将视频中的精彩部分,或者使用统一的封面作为视频的首帧呈现,当视频发布到视频平台的时候,就更容易吸引用户点击。
从下面的截图可以看出,在拥有几十上百个视频的前提下,手动操作插入首帧的流程比较繁琐。将其自动化可以节省大量的人力,避免出错的可能。

那么,为什么要将首帧插入和漫剧字幕烧录做成一个 Skill,而不是分开呢?
主要有两个原因:
- 重新烧录视频,是一个全新的转码过程,对视频质量有一定的影响,应该避免对原始视频进行多次转码。
- 转码对计算机性能是较大的考验,需要消耗较长的时间,一次性转码能节省时间,降低能源消耗(保护环境😄)。
漫剧字幕 + 首帧烧录 manju-burn
这个 Skill 使用 ffmpeg 烧录字幕和首帧进入最终视频:
- 将封面加入到视频首帧。
- 获取无字幕的原始视频。
- 使用和原始视频完全相同的码率、帧率、分辨率,加入人声和字幕,重新生成目标视频文件。
开发过程中,有两个问题值得拿出来说道说道。
对不同语言提供不同的字体
完全使用系统字体也不是不能用,但在字幕的表现力上会略有逊色。以下是曾老师的建议:
- 对于日文字体,建议采用
Hiragino Sans W6。 - 印尼语、巴西葡萄牙语、英语同属拉丁语系,但前两者需要重音符号支持,选择一个对重音符号支持较好的拉丁语系字体即可,这里选择的是:
Arial Unicode MS。
并行烧录的选择
保守起见,在我的设备上采用的是 2 进程同时烧录。如果设备配置更高,可以酌情开启多进程。
只需要对大模型提出:
开启 2 个 subagent,调用 manju-burn 进行字幕烧录。
(核心的经验积累,见文章末尾)
SKILL.md
1---
2name: manju-burn
3description: |
4 漫剧多语言字幕烧录与首帧封面合成工具。通过 FileBrowser 读取剧集目录中的无字幕视频、多语言 SRT 字幕和海报封面,调用 ffmpeg/libass 按固定 ASS 样式烧录字幕,并将对应语言封面替换为输出视频首帧。
5 当用户提到"烧录字幕"、"字幕压制"、"字幕硬字幕"、"manju-burn"、"漫剧烧录"、"封面首帧"、"多语言成片"、"ffmpeg字幕"时使用此技能。
6---
7
8# Manju Burn - 多语言字幕烧录与首帧封面合成
9
10你是一个专业的视频后期自动化工程师。使用本 Skill 时,优先调用随 Skill 提供的脚本完成确定性工作,不要手写临时 ffmpeg 命令。
11
12## 核心能力
13
14- 从 FileBrowser 读取剧集目录中的无字幕视频、SRT 字幕和海报封面
15- 默认处理英语、巴西葡萄牙语、日语、印尼语四种语言
16- 如果用户指定语言,只处理指定语言
17- 使用 ffmpeg/libass 将 SRT 转为 ASS 并烧录为硬字幕
18- 将对应语言封面缩放裁切到视频尺寸后替换为输出视频首帧
19- 将成片输出到 FileBrowser 的 `成片/<语言名>有封面/`
20- 本地目录分为 `cache/`、`work/`、`final/`:输入素材缓存、中间 ASS、最终成片分开管理。
21- 本地最终成片按语言平铺:`outputs/manju-burn/<剧集名>/final/<语言代码>/<集数>.mp4`
22- 远端目录创建和成片上传统一调用 `filebrowser-quantum` 的共享客户端方法;不要在 manju-burn 中手写 FileBrowser 上传请求。
23
24## 目录约定
25
26剧集根目录由 `agent_config.toml` 的 `[manju-burn].series_root` 决定。单个剧集路径为:
27
28{series_root}/{剧集名称}/
29
30默认目录:
31
32{剧集}/成片/无字幕/ # 输入视频
33{剧集}/字幕/英文SRT/ # 英语字幕
34{剧集}/字幕/巴西葡萄牙语SRT/ # 巴西葡萄牙语字幕
35{剧集}/字幕/日语SRT/ # 日语字幕
36{剧集}/字幕/印尼语SRT/ # 印尼语字幕
37{剧集}/海报封面/英语/ # 英语封面
38{剧集}/海报封面/巴西葡萄牙语/ # 巴西葡萄牙语封面
39{剧集}/海报封面/日语/ # 日语封面
40{剧集}/海报封面/印尼语/ # 印尼语封面
41{剧集}/成片/<语言名>有封面/ # 输出视频
42
43## 语言映射
44
45| 参数 | 字幕目录 | 封面目录 | 输出目录 |
46|---|---|---|---|
47| `en` | `英文SRT` | `英语` | `英语有封面` |
48| `pt-br` | `巴西葡萄牙语SRT` | `巴西葡萄牙语` | `巴西葡萄牙语有封面` |
49| `ja` | `日语SRT` | `日语` | `日语有封面` |
50| `id` | `印尼语SRT` | `印尼语` | `印尼语有封面` |
51
52支持常见别名:`english`、`英语`、`pt`、`葡萄牙语`、`jp`、`日本语`、`indonesian`、`印尼语`。
53
54## 文件匹配规则
55
56- 以 `成片/无字幕/*.mp4` 为主文件列表。
57- 字幕按同名匹配,例如 `C01-10_1.mp4` 匹配 `C01-10_1.srt`。
58- 封面按视频文件名里的首个集数匹配 `ep{n}.png`,例如:
59 - `C01-01_1.mp4` -> `ep1.png`
60 - `C01-10_1.mp4` -> `ep10.png`
61 - `C01-10_2.mp4` -> `ep10.png`
62- 如果同名字幕或对应封面不存在,跳过该视频并在报告中列出缺失项。
63
64## 字幕样式
65
66脚本会将 SRT 转换为 ASS,并使用以下样式。字体按语言选择,默认从 `manju-burn/fonts/` 读取:
67
68- 英语、巴西葡萄牙语、印尼语:`Arial Unicode MS`
69- 日语:`Hiragino Sans W6`
70
71SUBTITLE_STYLE = {
72 "PlayResY": 1920,
73 "FontName": "<按语言选择>",
74 "FontSize": 90,
75 "PrimaryColour": "&H00FFFFFF",
76 "OutlineColour": "&H00000000",
77 "Outline": 3,
78 "Shadow": 0,
79 "Alignment": 2,
80 "MarginV": 580,
81}
82
83如果当前机器的 ffmpeg/libass 无法解析指定字体,默认只警告并继续执行。
84
85## 标准命令
86
87始终从项目根目录运行:
88
89uv run --project manju-burn/scripts manju-burn/scripts/burn_subtitles.py \
90 --series "C01" \
91 --non-interactive
92
93只处理指定语言:
94
95uv run --project manju-burn/scripts manju-burn/scripts/burn_subtitles.py \
96 --series "C01" \
97 --languages ja,id \
98 --non-interactive
99
100只处理指定集数或分段:
101
102uv run --project manju-burn/scripts manju-burn/scripts/burn_subtitles.py \
103 --series "C01" \
104 --episodes 10
105
106预检远程匹配关系,不下载、不烧录、不上传:
107
108uv run --project manju-burn/scripts manju-burn/scripts/burn_subtitles.py \
109 --series "C01" \
110 --dry-run \
111 --non-interactive
112
113只生成本地文件,不上传:
114
115uv run --project manju-burn/scripts manju-burn/scripts/burn_subtitles.py \
116 --series "C01" \
117 --local-only \
118 --non-interactive
119
120## 工作流
121
1221. 确认用户提供了剧集名称。未提供时要求补充。
1232. 读取 `agent_config.toml`,连接字段优先使用 `[manju-burn]`,否则回退到 `[filebrowser-quantum]`。
1243. 读取剧集的输入视频、字幕目录和封面目录。
1254. 按语言和集数参数生成任务清单。
1265. 非 dry-run 时下载素材到 `outputs/manju-burn/<剧集>/cache/`:无字幕视频放 `cache/videos/`,SRT 放 `cache/subtitles/<语言代码>/`,封面放 `cache/covers/<语言代码>/`。
1276. 将 SRT 转 ASS,ASS 中间文件放 `work/ass/<语言代码>/`。
1287. 调用 ffmpeg 烧录字幕并替换首帧封面,输出直接写入 `final/<语言代码>/<集数>.mp4`,例如 `final/en/01.mp4`、`final/ja/02.mp4`。
1298. **上传安全规范**:
130 - 必须先确认远程输出目录存在。
131 - 上传必须使用 `filebrowser-quantum` 的共享客户端 `upload_file_to_dir()`。
132 - 上传目标必须是远端目录路径,客户端会规范为 `/` 结尾;远端文件名通过 `remote_name` 指定,例如本地 `final/en/01.mp4` 上传为远端 `C01-01.mp4`。
133 - 严禁在 manju-burn 内自行构造 multipart/form-data 或直接 POST 完整 `.mp4` 文件路径。
1349. 汇报成功、跳过和缺失文件清单。
135
136## 质量检查
137
138完成后必须确认:
139
140- 输出 MP4 能被 `ffprobe` 读取
141- 输出视频首帧来自对应语言封面
142- 字幕已作为硬字幕烧录,不再依赖外部字幕文件
143- 未指定 `--overwrite` 时不覆盖已有远程输出
144- dry-run 不修改远程文件
145
146## 配置
147
148在项目根目录的 `agent_config.toml` 中添加:
149
150```toml
151[manju-burn]
152series_root = "/虎澈漫剧"
153subtitle_folder = "字幕"
154input_video_folder = "成片/无字幕"
155cover_folder = "海报封面"
156output_parent_folder = "成片"
157output_suffix = "有封面"
158fonts_dir = "manju-burn/fonts"
159font_name = "Arial Unicode MS"
160font_warning_policy = "warn"
161video_codec = "libx264"
162crf = 18
163preset = "medium"
164
165[manju-burn.language_fonts]
166en = "Arial Unicode MS"
167pt-br = "Arial Unicode MS"
168ja = "Hiragino Sans W6"
169id = "Arial Unicode MS"
170
171`base_url`、`token`、`default_source` 可不写;未设置时自动使用 `[filebrowser-quantum]` 的连接配置。
172```
(scripts 内容略过……)需要详细内容可进入胡扯漫剧/胡扯 AI 群获取。
开始烧录
这是在我的电脑 MacBook Pro M4 上开启 2 个 subagent 烧录时的系统负载。此时系统已经跑满,不建议同时做其他工作了。
如果有 64 GB 以上内存,以及 16 核以上 CPU 或独立显卡,可以考虑开启 FFmpeg 的硬件编码支持,将烧录提升到 4-8 并行。

经验积累和 Codex 5.5/DeepSeek V4/Gemini 3 大模型对比
在字幕翻译以及字幕烧录这两个 Skill 的开发过程中,曾老师一直在深度使用上面三个大模型和工具,下面是我的体验(一家之言,仅供参考)。
- Codex 5.5 是真的强。相同的提示词,它都能一次完整搞定,极少出错,还能经常给出让人很惊喜的专业建议。
- DeepSeek V4 和 Gemini 3 我认为在使用过程中的表现都差不多。属于小错不断,大错也犯的状态。但我认为,在边界清晰明确的前提下,已经能作为一个基础的实习生来使用了。哦不,比基础的实习生还要靠谱一些。
- 一定要在提示词中做好边界的控制。作为 Skill 编写者,尽量在
skill/scripts级别加入严格控制,要求大模型严格遵循skill/scripts中的工具说明,不允许自编 script 绕过skill/scripts调用。 - 设计 Skill 的时候也要遵循 KISS 原则,让一个 Skill 做好一件事。在本例中,所有的大模型都试图自己写代码去调用 FileBrowser(见上篇)的 API,但均被我严格禁止。因为有一个大模型(就不说是谁了)甚至直接用 API 覆盖了 FileBrowser 上的一个文件夹(导致无法恢复)。如果严格遵循 KISS 原则,只需要在 FileBrowser 的
skill/scripts中进行严格限制,就能永久避免这种情况。
上篇: 漫剧全自动字幕翻译 Skill:Codex 5.5/DeepSeek V4/Gemini 3 混战
(打赏本文进入胡扯 VIP-AI 群,获取完整 Skill/scripts)
- 文章ID:2864
- 原文作者:zrong(Jacky)
- 原文链接:https://blog.zengrong.net/post/manju-subtitle-first-frame-burn-skill/
- 版权声明:本作品采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可,非商业转载请注明出处(原文作者,原文链接),商业转载请联系作者获得授权。