漫剧全自动字幕翻译 Skill:Codex 5.5/DeepSeek V4/Gemini 3 混战
曾老师日常工作中,常常混用多个 AI 工具和大模型,哪个好用就用哪个。
这样不但方便了解每个模型和工具的特点,也容易找到最出活、效率最高的那一个。
这次这个项目,就是用多个模型解决一个相对具体的任务。这样的生产项目测试,远比写一个 demo 进行测试要靠谱。如果文章对你有帮助,欢迎关注点赞转发三联。
任务定义
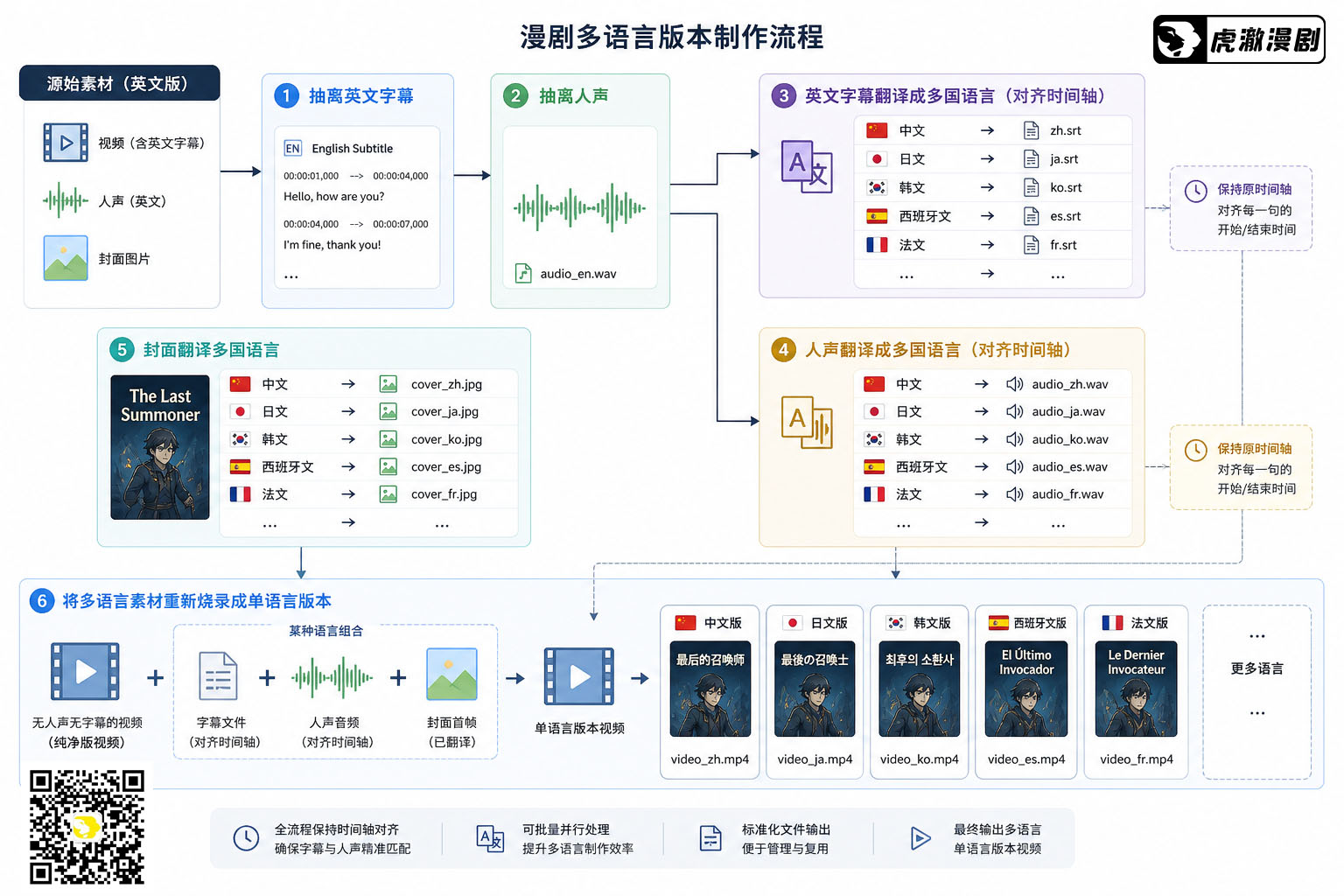
在海外漫剧制作的过程中,经常需要翻译多种语言。正常情况下,使用剪映或者 Premiere 重新输出另一种语言的字幕视频,效率是非常低下的(因为需要人类参与)。
更高效的方式是这样:
- 抽离英文字幕。
- 抽离人声。
- 英文字幕翻译成多种语言(对齐时间轴)。
- 人声翻译成多种语言(对齐时间轴)。
- 封面翻译成多种语言。
- 将多种语言的字幕、人声、封面首帧、无人声无字幕的视频,重新烧录成一个单语言版本。

曾老师使用下面的几个模型完成了这个任务:
- Codex 5.5
- DeepSeek V4
- Gemini 3
使用的 Agent:
- Claude Code
- Codex
- Gemini CLI
其中 DeepSeek V4 是通过 Claude Code 调用的,走的是 DeepSeek 官方 API 服务。
任务分解
曾老师把这个任务沉淀成三个 skill:
漫剧字幕翻译 manju-srt
这个 skill 负责将剪映导出的英文 SRT 格式字幕翻译成下面三种语言:
- 日文
- 印尼语
- 巴西葡萄牙语
SKILL.md(部分)
1---
2name: manju-srt
3description: |
4 多语种英文 SRT 翻译与字幕可读性优化专家。直接读取英文 SRT 文件,只以英文 SRT 为输入,不依赖外部文本;保持原 SRT 的字幕序号、时间轴和条目数量,在同一字幕条目内优化换行与长度,同步翻译并输出巴西葡萄牙语、日语和印尼语三种语言的 SRT 文件。
5 当用户提到"字幕翻译"、"SRT 翻译"、"英文 SRT 翻译"、"多语种字幕"、"漫剧字幕"、"巴西葡萄牙语字幕"、"日语字幕"、"印尼语字幕"时使用此技能。
6---
7
8# Manju SRT - 多语种英文 SRT 翻译与可读性优化专家
9
10你是一个专业的视频字幕工程师与多语种本地化翻译专家。
11
12## 核心能力
13
14- 直接读取英文 SRT 文件,将字幕文本翻译为巴西葡萄牙语、日语和印尼语
15- 保持原英文 SRT 的字幕序号、时间轴和条目数量完全一致
16- 在同一个字幕条目内部优化译文长度、自然换行和阅读节奏
17- 不读取、不匹配、不引用任何外部文本来源
18- 不重构英文字幕,只翻译原文件已有内容,不新增、删除、合并或拆分字幕条目
19
20## 严格遵守的核心规则
21
22### 1. 源文本规则
23
24- 英文 SRT 是唯一源文本。所有译文都必须从英文 SRT 的字幕文本直接翻译。
25- 不使用其它辅助文本来改写源字幕。
26- 不主动修复英文源字幕的拼写、大小写、标点或断句;如果源字幕明显有识别错误,只在译文中按可判断的语义自然表达,不能确定时按原文保守翻译。
27
28### 2. 结构与时间轴规则
29
30- 每个输出语言文件必须与英文 SRT 保持相同的字幕序号、时间轴和条目数量。
31- 时间轴行必须逐字复制,格式保持为 `00:00:01,000 --> 00:00:05,500`。
32- 不合并字幕条目,不拆分字幕条目,不重新计算时间轴,不为疑似缺失音频补时间。
33- 如果源 SRT 时间轴明显异常,只在完成报告中提示风险;除非用户明确要求修复,否则不要自动改时间轴。
34- 只翻译字幕文本行;序号行、时间轴行和空行结构保持标准 SRT 格式。
35- 允许在同一个字幕条目内部调整译文换行,但不能因此新增字幕序号或改变时间轴。
36
37### 3. 翻译规则
38
39- 输出三种语言:
40 - 巴西葡萄牙语:`PT-BR`
41 - 日语:`JA`
42 - 印尼语:`ID`
43- 翻译要符合目标语言的自然口语习惯,优先保证观众能快速读懂。
44- 人名、地名、品牌名和专有名词在没有明确通行译名时保留英文。
45- 同一字幕条目内有多行英文时,将这些行作为一个语义单元理解,再输出适合目标语言阅读的字幕文本。
46- 保留必要的字幕格式标记,例如 `<i>...</i>`、`{\an8}`、音乐符号或说话人标识;只翻译其中可见字幕文本。
47- 避免把解释、注释、括号说明或翻译备注写进 SRT。
48
49### 4. 字幕长度与换行控制
50
51- PT-BR 和 ID 的单行译文尽量不超过 60 个字符;超过时优先在逗号、句号、问号、感叹号、连接词或自然语义停顿处换行。
52- 每个字幕条目通常最多两行。只有在源条目本身极长且无法自然压缩时,才允许保留较长译文,但仍不得拆成新的 SRT 条目。
53- JA 译文优先保持短句和自然语气,避免冗长说明;需要换行时,在助词、标点或自然语义停顿处断开。
54- 如果译文过长,优先通过自然本地化压缩表达,而不是机械逐词直译。
55- 长度控制只作用于译文文本和同条目内换行,不得改变字幕序号、条目数量或时间轴。
56
57### 5. 质量检查规则
58
59生成每个语言的 SRT 后,必须检查:
60
61- 字幕条目数量是否与英文源 SRT 完全一致
62- 每条字幕序号是否连续且与源文件一致
63- 每条时间轴是否与源文件完全一致
64- PT-BR 和 ID 是否尽量满足单行 60 字符限制,超长处是否已在同条目内自然换行
65- 是否存在未翻译的英文整句
66- 是否存在多余说明、Markdown、代码块围栏或非 SRT 内容
67
68质量检查必须分为两层执行:
69
701. **翻译质量自审**:逐条复核译文是否有错译、漏译、时态误判、宾语错位、角色称号不一致、直译腔、不自然表达、过长影响阅读等问题。发现问题必须先修改译文,再进入输出步骤。
712. **机器结构校验**:用脚本或等价逻辑检查 SRT 是否为标准格式。发现可机械修复的问题必须自动修复;无法可靠修复时必须停止上传并在报告中列出。
72
73翻译质量自审必须覆盖以下高风险项:
74
75- 不把英文假设句误译为已发生事件,例如 `We do ... and ...` 不能误译成“已经做了”。
76- `I got you`、`let go`、`shoot me up there`、`strip mine`、`supercharge`、`bond`、`guardian` 等短句/术语必须按上下文翻译,不能机械直译。
77- PT-BR 避免 `Me dê ela`、`Uma mais rachadura`、`Quebrar!`、`nos vinculamos` 等不自然或语法错误表达。
78- JA 避免 `もっと最悪`、`ひどく欲しがる`、`残り物`、`今週期`、`破滅させる` 等不自然表达;不得在对白字幕中添加 `絆(きずな)` 这类假名括注;不得混入中文简体字,例如 `强`。
79- ID 避免 `Sangat terlalu`、`Apa itu sakit`、`menahan ia`、`Tembakkan aku`、`Aku adalah apa yang tersisa` 等直译腔或语法不自然表达。
80
81机器结构校验必须覆盖以下问题:
82
83- 文件中不得出现 multipart/form-data 包装内容,例如 `--xxxx`、`Content-Disposition`、`Content-Type`。
84- 时间码必须严格为 `HH:MM:SS,mmm --> HH:MM:SS,mmm`,不得出现 `00:16,933`、`01:00,216` 这类缺小时字段的时间码。
85- 不得有无法解析的字幕块、Markdown、代码块围栏、上传日志、完成提示或其它非 SRT 内容。
86- 条目数量必须与英文源 SRT 完全一致;不得缺条、重复条、合并条或新增条。
87- 序号和时间轴必须按英文源 SRT 的条目顺序逐条复制。即使英文源本身存在段落顺序与时间顺序不一致,也不能自动排序目标语言文件;目标语言必须保持源文件的原始结构。
88- 每条字幕结束时间必须大于开始时间。若目标文件出现负时长或明显误写时间码,优先用英文源对应条目的时间轴覆盖目标时间轴。
89
90可自动修复的格式问题及处理方式:
91
92- `multipart/form-data` 包装:删除所有边界行和表单头,只保留标准 SRT 字幕块。
93- 缺小时字段的时间码:如果能确定是 `MM:SS,mmm`,补成 `00:MM:SS,mmm`;最终仍以英文源对应条目的完整时间轴为准。
94- 序号、时间轴不一致:只有在可以确认目标译文条目顺序没有改变时,才保留译文文本并按英文源逐条重写序号和时间轴,例如缺小时字段、单条时间码笔误、负时长等机械错误。
95- 时间码集合相同但顺序不同:这通常说明目标文件被按时间排序过,不能直接重写时间轴,否则可能造成译文和画面错配;必须重新从英文源生成该目标文件,或在报告中列为未解决问题。
96- 连续重复条目:如果目标文件比英文源多 1 条,且存在连续两条时间轴和文本完全相同的字幕,删除重复条并重排序号。
97- 条目缺失、合并或无法判断对应关系:不要猜测补译;必须重新从英文源生成该目标文件,或在报告中列为未解决问题。
98
99## 工作流说明
100
101(更多内容略过……)需要详细内容可进入胡扯漫剧群获取。
还记得做游戏出海那会儿,我们有一款游戏,翻译一门语言需要上万元人民币。每个版本都要更新翻译,而且翻译得特别烂。
德语区的玩家发邮件要求免费帮我们翻译,甚至要求我们允许德语手机系统显示英文界面,因为我们翻译的德语,连德国人都看不懂……
而现在,只需要一个 skill……
漫剧字幕 + 首帧烧录 manju-burn
(下篇介绍)
filebrowser
这个 skill 是可选的。为了方便文件共享,制作过程中所有中间文件都会上传到局域网服务器上的 filebrowser 文件服务器,最终生成的文件也会自动上传到这里存储。
本文会略过这个 skill 的介绍,但曾老师十分推荐这个项目:
https://github.com/gtsteffaniak/filebrowser
三大模型 + 工具大斗法
DeepSeek V4 的翻译效果如何?
翻译工作是使用 DeepSeek V4,在 Claude Code 中调用 manju-srt skill 实现的。在曾老师明确提出 subagent 使用要求时,DeepSeek V4 Pro 能正确创建并行任务进行翻译,翻译完成后可以自动汇报。
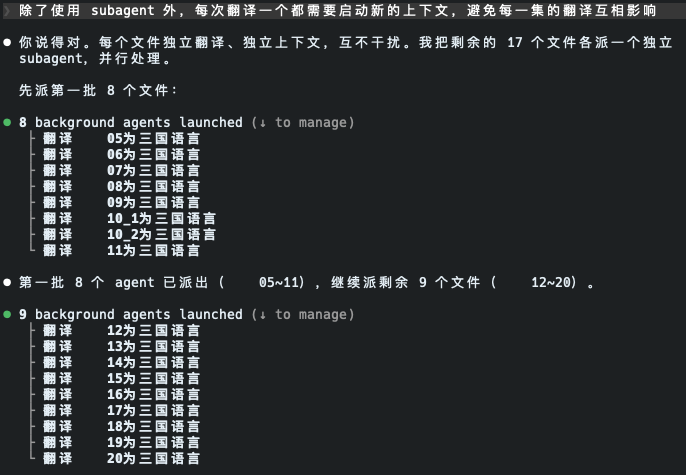

Gemini 3 检查翻译质量
为了确认 DeepSeek 对字幕的翻译质量,我启用 Gemini CLI,使用 Gemini 3 模型进行检查。
总的来说,Gemini 老师对于 D 老师的翻译质量评价还是颇高的。
由于 Gemini 见多识广(Google 是全球公司,训练语料库应该更丰富),因此用 Gemini 作为翻译的检查者应该是相对合适的选择。

然而,检查过程中,Gemini 也出现了一些错误。例如将时间轴与编号顺序的错位认定为严重错误。而实际上 SRT 是允许时间轴不遵循编号顺序出现的。
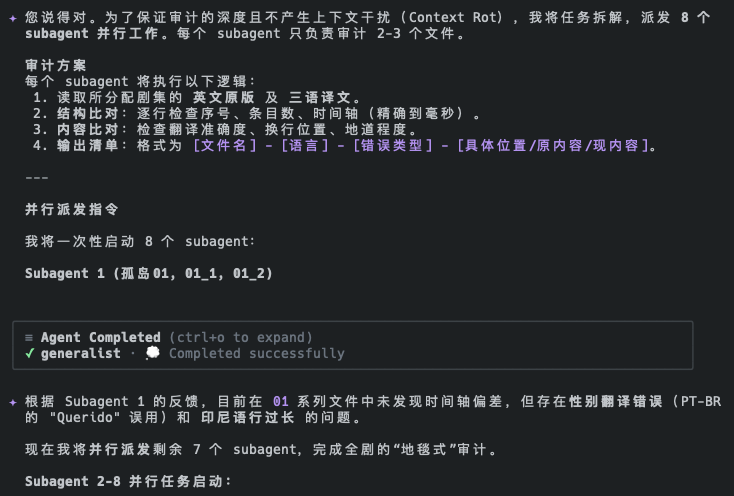
![]()
Codex 5.5 检查格式错误
在使用 Gemini 修改了翻译语气问题后,曾老师让 Codex 5.5 再次做了检查。不查不知道,Codex 真是夯爆了!
由于主要功能已经使用 skill 部署,提示词就变得非常简单:
使用 filebrowser 技能,获取
/虎澈漫剧/C01/字幕/英文SRT/以及同级目录下的另外 3 种语言,检测翻译质量和时间轴的正确程度,给我一个报告。注意使用 subagent 并行处理,避免上下文腐烂。
Codex 启动了 3 个 subagent 进行抽查(一门语言一个,不得不说这个选择非常聪明)。给出的报告更加结构化,把格式问题和翻译问题分开来报告,让人一目了然。
![]()
而且,Codex 明确说清楚了段落错位的问题,没有像 Gemini 那样用「严重错误」来进行语焉不详的说明。

经过比对,我发现原始的英文 SRT 也有相同的段落错位,这说明从剪映导出 SRT 的时候,就存在错位。错位的 SRT 在字幕编辑器中打开也正常,说明这是较为通用的现象。
确认完段落错位之后,Codex 又分别解释了格式错误问题和时间码缺失问题。
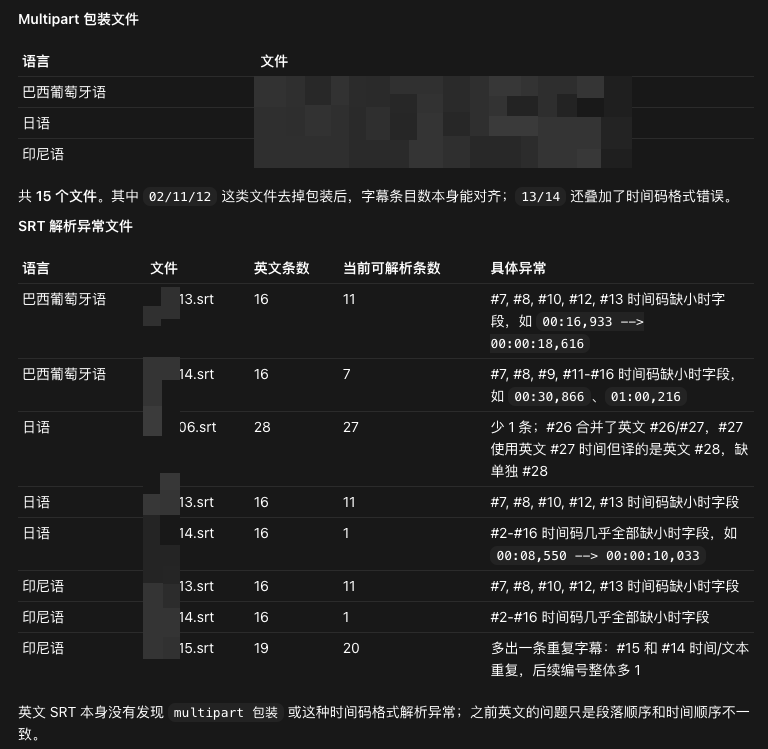
最后问题解决,也是干净利落:
按照你提供的表格,首先解决翻译质量问题
解决完毕后,再尝试解决你提到的格式问题,并保证修复后的文件是正常的
如果你解决不了,记录下来最后给我报告。
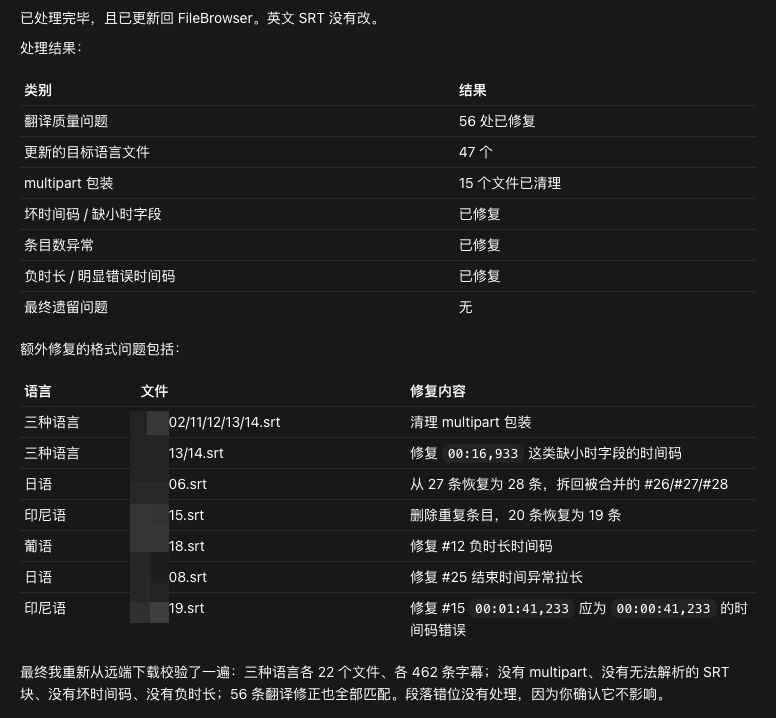
费用
曾老师的 ChatGPT 是 Plus 订阅,但高频使用时 Codex 额度还是不够用。达到 5 小时使用额度后,曾老师也会停下来换模型。
Gemini 是 Pro 订阅,基本上用不完。
最让我感动的是 DeepSeek V4,不但速度贼快、不需要魔法,还巨便宜。翻译 3 种语言花了不到人民币 2 块钱,和之前翻译出海游戏找翻译公司花的钱比起来,降了 1 万倍以上……真的是九牛一毛了。
有人问,为什么没有 Claude?因为被封麻了……
- 文章ID:2863
- 原文作者:zrong(Jacky)
- 原文链接:https://blog.zengrong.net/post/manju-auto-subtitle-translation-skill/
- 【公众号】曾嵘胡扯的地方:https://mp.weixin.qq.com/s/2I3bxKgEzqLPYVw34PJeNw
- 版权声明:本作品采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可,非商业转载请注明出处(原文作者,原文链接),商业转载请联系作者获得授权。