构建BI:查询引擎和数据仓库
文章目录
在 构建BI:大数据系统概念 一文中,我们提到过 OLAP 系统的特点:
OLAP 强调 SQL 执行时长,强调磁盘 IO、磁盘分区和磁盘子系统吞吐量。OLAP 同时处理的数据量大,DML 少,更多的执行是报表作业和聚合类操作。
这些特点让 OLAP 对于存储和查询的要求都很高。业界也有大量成熟的技术解决方案来处理这两类问题。
本文从个人喜好的角度来简单讨论查询引擎 Presto 和数据仓库 ClickHouse。
注意:本篇为技术讨论,对技术不感兴趣的读者可以跳过不看。
Presto
Presto 是一个分布式内存化 SQL 引擎,只负责计算,不负责存储数据。Presto 不会将中间结果写入磁盘,能显着提高查询速度。
Facebook 和社区
PrestoDB 是 2013 年 Facebook 的三个核心工程师创造并开源的产品。在 Facebook 内部,这个应用规模很庞大(总结点 10000+)。2018 年,Facebook 决定对 Presto 进行更严格的管控。为了自己创立项目的更好发展,这三个工程师离职创建了 Presto 软件基金会,fork 了 PrestoDB 的源码,创建了 PrestoSQL。
Facebook 随后在 LinuxFoundation® 上创建了 Presto 基金会,并申请了 Presto® 商标。
因为 Presto 已经是注册商标,三个创始人只能放弃这个由自己创建的名称,将 PrestoSQL 改名为 Trino。
因此,你可以在互联网上找到两个 Presto 版本:
曾嵘在这里建议选择 Trino。
详见: We’re rebranding PrestoSQL as Trino
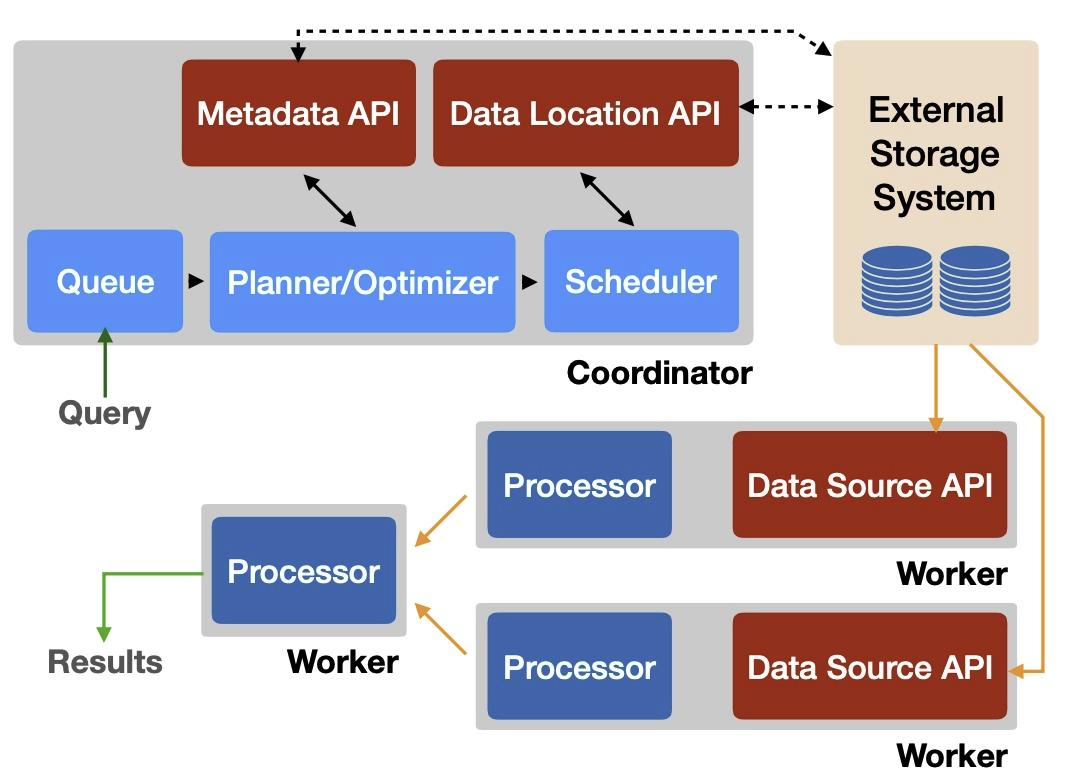
Presto 的优势
- 多数据源、混合计算支持:支持众多常见的数据源,并且可以进行混合计算分析;
- 大数据:完全的内存计算,支持的数据量完全取决于集群内存大小。他不像SparkSQL可以配置把溢出的数据持久化到磁盘,Presto是完完全全的内存计算;
- 高性能:低延迟高并发的内存计算引擎,相比Hive(无论MR、Tez、Spark执行引擎)、Impala 执行效率要高很多。根据Facebook和京东的测试报告,至少提升10倍以上;
- 支持ANSI SQL:这点不像Hive、SparkSQL都是以HQL为基础(方言),Presto是标准的SQL。用户可以使用标准SQL进行数据查询和分析计算;
- 扩展性:有众多 SPI 扩展点支持,开发人员可编写UDF、UDTF。甚至可以实现自定义的Connector,实现索引下推,借助外置的索引能力,实现特殊场景下的 MPP;
- 流水线:Presto 是基于PipeLine进行设计,在大量数据计算过程中,终端用户(Driver)无需等到所有数据计算完成才能看到结果。一旦开始计算就可立即产生一部分结果返回,后续的计算结果会以多个Page返回给终端用户(Driver)
Presto 的 Connector
借用 Connector 机制,Presto 可以将来自一切数据源的数据计算 SQL 化。
- 本地文件(File Connector)
- 内存(Memory Connector)
- HTTP API(Http Connector)
- Hive(Hive Connector)
- HBase(HBase Connector)
- MySQL(MySQL Connector)
ClickHouse
ClickHouse 由俄罗斯 Yandex 公司开源的数据仓库(Data Warehouse),专为 OLAP 而设计。
Yandex 是俄罗斯最大的搜索引擎公司,官方宣称 ClickHouse 中有超过 13 万亿条记录,每天超过 200 多亿个事件被处理。
ClickHouse 是 DBMS(database management system),有自己的数据存储机制:列式存储。
ClickHouse 的特性
- 真正的列式数据库管理系统
- 数据压缩
- 数据的磁盘存储
- 多核心并行处理
- 多服务器分布式处理
- 支持SQL
- 向量引擎
- 实时的数据更新
- 索引
- 适合在线查询
- 支持近似计算
- Adaptive Join Algorithm
- 支持数据复制和数据完整性
- 角色的访问控制
列式存储的优势
OLAP场景与其他通常业务场景(OLTP或K/V)有很大的不同,因此想要使用 OLTP 或 Key-Value 数据库去高效的处理分析查询场景,并不是非常完美的适用方案。
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍)
行式检索示意图
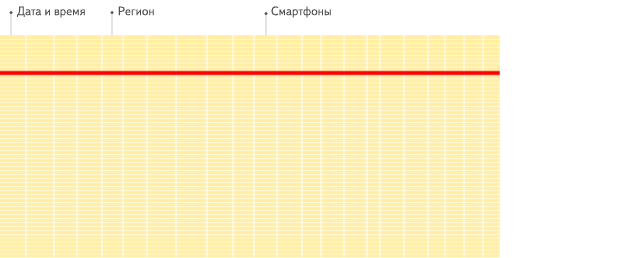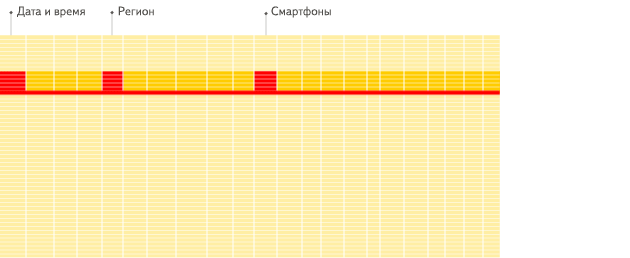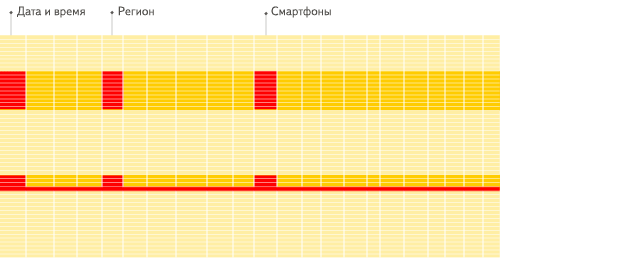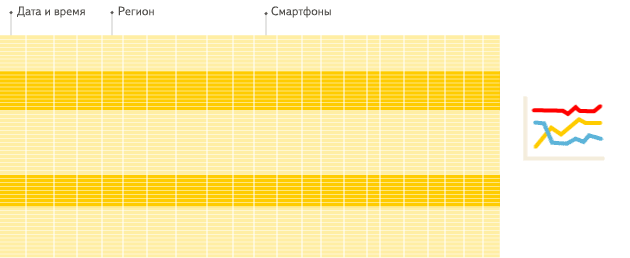
列式检索示意图
I/O
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。
MPP 架构和分布式架构
MPP 架构
MPP 架构是传统数据仓库中的常见技术架构,将单机数据库节点组成集群,从而提升处理性能。
ClickHouse 采用的是 MPP 架构。
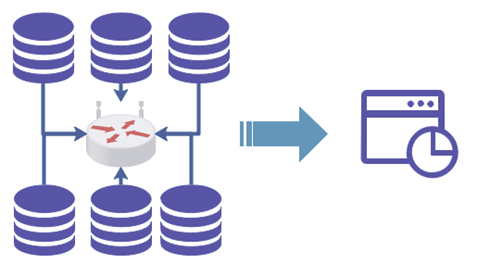
MPP 架构在集群中使用非共享形式,每个节点拥有独立的磁盘存储和内存系统,计算过程独立,单个节点不关心整个集群的状态。各节点之间的数据传输使用网络进行。
MPP 集群作为一个整体向外提供服务,单个节点无法独立运行局部应用。数据存储位置不透明,并行计算时,单节点瓶颈会成为整个系统的短板,扩展性较差。
分布式架构
分布式架构组成的集群中,各节点实现场地自治,可以独立运行局部应用。
Hive 采用的是分布式架构。
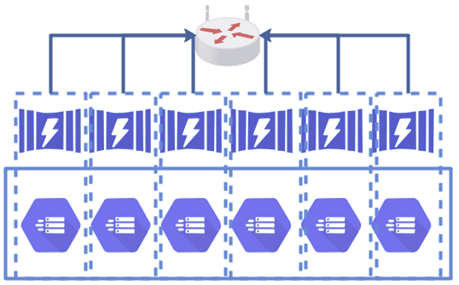
在分布式架构中,数据在集群中是全局透明共享的。节点在进行运算时,可以访问公共数据存储系统。
分布式架构对于网络的要求不高,但节点间的通信开销比较大,数据移动不方便。
主流的大数据仓库和查询引擎
下面都是些耳熟能详,大名鼎鼎、如雷贯耳、非常成熟的解决方案。仅列出简单介绍。
- Apache Hadoop: Hadoop 是一款支持数据密集型分布式应用程序的开源软件框架。用于高效存储和处理从 GB 级到 PB 级的大型数据集。利用 Hadoop,您可以将多台计算机组成集群以便更快地并行分析海量数据集,而不是使用一台大型计算机来存储和处理数据。Hadoop 是根据谷歌公司发表的 MapReduce 和 Google 文件系统的论文自行实现而成。它包含 HDFS、YARN、MapReduce 和一套 JAVA 库。
- Apache HBase:HBase 是一种开源 NoSQL 分布式大数据存储。它可以实现对 PB 级数据的随机、严格一致的实时访问。HBase 可非常高效地处理大型稀疏数据集。可以在 Hadoop 分布式文件系统 (HDFS) 顶部运行。
- Apache Spark:Spark 是一种用于大数据工作负载的分布式开源处理系统。它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询。它提供使用 Java、Scala、Python 和 R 语言的开发 API,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。Spark 和 Presto 类似,没有自己的存储系统。
- Apache Hive: Hive 是可实现大规模分析的分布式容错数据仓库系统。该数据仓库集中存储信息,您可以轻松对此类信息进行分析,从而做出明智的数据驱动决策。Hive 让用户可以利用 SQL 读取、写入和管理 PB 级数据。Hive 建立在 Apache Hadoop 基础之上。
- Apache Kafka:Kafka 是一种分布式数据存储,经过优化以实时提取和处理流数据。流数据是指由数千个数据源持续生成的数据,通常可同时发送数据记录。流平台需要处理这些持续流入的数据,按照顺序逐步处理。Kafka 适合在 ETL 系统中发挥作用。
参考文章
- 开源OLAP引擎综评:HAWQ、Presto、ClickHouse
- 第1章02节 | Presto概述:特性、原理、架构
- Presto: Interacting with petabytes of data at Facebook
- Presto 分布式SQL查询引擎及原理分析
- greenplum,teradata,presto,clickhouse四种分布式数据库的对比
- ClickHouse拆解
- 【简介】MPP&分布式架构
- We’re rebranding PrestoSQL as Trino
- 什么是ClickHouse
- 文章ID:2759
- 原文作者:zrong(Jacky)
- 原文链接:https://blog.zengrong.net/post/build-bi-2/
- 版权声明:本作品采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可,非商业转载请注明出处(原文作者,原文链接),商业转载请联系作者获得授权。