构建BI:大数据系统概念
我正在构建一个用于游戏运营的 BI(Busniness Intelligence)系统,该系统用于指导 SAGI GAMES 游戏的投放,把运营和投放岗位从重复繁重的数据分析工作中解放出来。
我会用文字把整个构建中的学习、思考、决策的流程记录下来,形成这个系列: 构建BI。
由于时间仓促,能力有限,这个系列中一定有许多疏漏错误之处,欢迎指出和讨论。
本文的目标是理解大数据系统的相关概念。
生产-存储-消费
计算广告是唯一得到充分商业化的规模化的大数据应用。BI(Business Intelligence)系统属于一种大数据洞察应用。它处在 生产、存储、消费 流程中的消费环节。
参见:计算广告:免费模式的本质
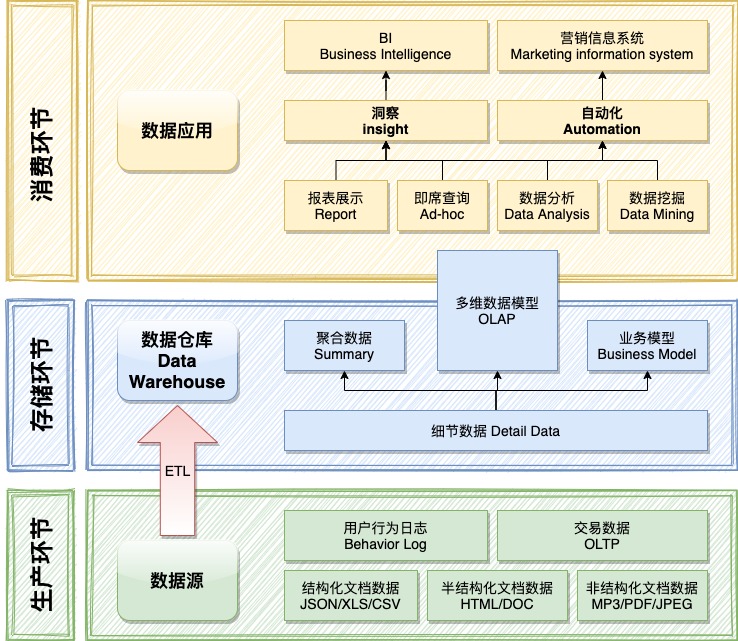
图中,数据源 处于生产环节,数据仓库 处于存储环节,数据应用 属于消费环节。
BI 系统,在商业上属于 DDS(Decision support system,决策支持系统),作用是将源数据整理到数据仓库(Data Warehouse) 中,然后根据业务模型对仓库中的数据进行分析、聚合,最终在数据应用层面展示出来。
源数据
在数据生产环节,源数据可能有多种来源,例如来自于 OLTP 的交易数据和行为数据,来自于文档的结构化数据,和来自于图像、声音等非结构化数据。
数据仓库
数据仓库(Data Warehouse)处于存储环节。我们根据业务模型对数据源中的数据进行抽取、清洗、转换、聚合,将处理过的源数据存储进入数据仓库备用。整个处理的过程被称为 ETL。
数据应用
在 计算广告:免费模式的本质 一文中,我们提到了两种大数据应用:
- 洞察(insight)
- 自动化(automation)
BI 属于一种洞察应用。营销信息系统属于一种自动化应用。
重要概念介绍
OLTP
OLTP 是 On-line Transaction Processing 的简称,中文一般译为 联机事务处理。传统银行交易就是典型的 OLTP 应用。
技术上,OLTP 强调内存各种指标的命中率,强调查询效率,强调并发,高可用。OLTP 评估 Transaction 和 Execute SQL 的数量,对 IOPS 敏感,在硬件上对 CPU 和磁盘子系统依赖极高。
从数据的角度看,OLTP 同时处理的数据量少,DML(Data Manipulation Language) 频繁,并行事务处理多,但是一般都很短。
OLAP
OLAP 是 On-line Analytical Processing 的简称,中文一般译为 联机分析处理。BI 应用也可以说是一种 OLAP。
技术上,OLAP 强调 SQL 执行时长,强调磁盘 IO、磁盘分区和磁盘子系统吞吐量。Cache 在 OLAP 系统中的作用有限,因为要并行在多个数据源读取海量的数据,OLAP 在硬件上对于带宽和分布式磁盘个数要求高。
从数据的角度看,OLAP 同时处理的数据量大,DML 少,更多的执行是报表作业和聚合类操作。典型的操作是全表扫描,长查询,一般事务的个数很少,往往是一个事务独占系统。
需要注意的是,OLAP 是一个同时存在于存储环节和消费环节的概念。
OLTP 和 OLAP 的比较
| 项目 | OLTP | OLAP |
|---|---|---|
| 使用场景 | 在线业务 | 数据分析,挖掘、机器学习 |
| 主要用户 | 操作人员 | 决策人员 |
| 作用 | 日常操作 | 分析决策 |
| 实现 | 增删改查 | 复杂聚合与多数据源关联 |
| 数据新鲜度 | 当前的业务数据 | 历史的存档数据 |
| 数据维度 | 细节的,二维分立的 | 聚集的,多维统一的 |
| 数据量级 | 百MB~GB | 百GB~TB |
| 存取 | 读/写 数百条 | 读 百万条 |
| 并发 | 高 | 低 |
| 可用性 | 非常高 | 中 |
| 时间维度 | 毫秒 | 分钟、小时、天 |
| 技术方案 | 事务、索引、存储计算整合 | 大量 SCAN、列式存储、存储计算分离 |
| 数据模型 | 关系模型、3NF范式 | 维度模型、关系模型、范式要求低 |
| 典型技术 | MySQL/Oracle | Hadoop/Presto/ClickHouse |
| 典型应用 | 银行事务 | BI |
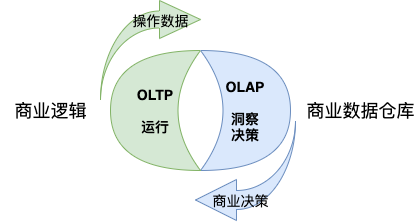
上面的表格主要讲区别,下面这张图可以体现 OLTP 和 OLAP 的联系:
OLTP 系统基于商业逻辑运行,生成的操作数据通过 ETL 进入数据仓库,OLAP 系统基于数据仓库进行分析,形成洞察和决策,反过来影响和改善商业逻辑。
OLAP 场景的关键特征
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许数十毫秒的延迟
- 列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
ETL
ETL 是 Extract-Transform-Load 的缩写,中文一般译为 抽取、清洗转换、加载。
ETL 是数据整合方案,也是数据整理工具,ETL 处理的数据量巨大,它不是一次性的活动,而是一个周期性的活动。
在数据抽取阶段,需要考虑同源数据,不同源数据,文件型数据(txt、xls)和增量更新。
在数据清洗阶段,需要考虑不完整数据、错误数据和重复数据。
在数据转换阶段,需要考虑的内容更多:
- 不一致的数据转换(例如用户唯一 id 的不同表现形式)
- 数据的粒度分析
- 理解商务规则。
简化概念
让我们把概念简化一下。将生产环节的数据源简化为 OLTP,将存储环节的数据仓库简化为 OLAP,那么 OLTP/ETL/OLAP 三者间的关系就是:
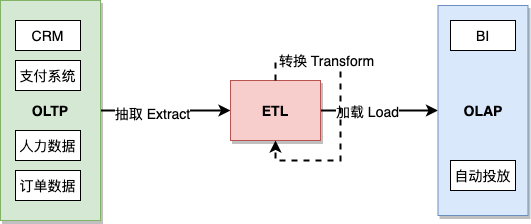
- 交易生成数据
- 多渠道抽取数据
- 清洗和转换数据
- 加载数据
- 分析数据
参考文章
- OLAP、OLTP的介绍和比较
- 第1章04节 | 常见开源OLAP技术架构对比
- ETL讲解(很详细!!!)
- 如何理解关系型数据库的常见设计范式?
- greenplum,teradata,presto,clickhouse四种分布式数据库的对比
- 数据仓库的基本架构
- 数据仓库的多维数据模型
- 文章ID:2758
- 原文作者:zrong(Jacky)
- 原文链接:https://blog.zengrong.net/post/build-bi-1/
- 版权声明:本作品采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可,非商业转载请注明出处(原文作者,原文链接),商业转载请联系作者获得授权。