给龙虾 nanobot 增加局域网访问能力:一次最小改动的白名单改造
文章目录
nanobot 是一个只有 4000 行代码,Python 实现的类 OpenClaw 智能体。我在 Windows 系统中使用它,有两个益处:
- 规避 OpenClaw 中的运行环境问题
- 解决安全问题,4000 行代码很容易阅读和修改
曾老师修改过的项目在此,关注 private_network 分支:
http://github.com/zrong/nanobot.git
使用 nanobot 的时候,我碰到一个很实际的问题:我希望它能访问局域网中的服务。
例如,我有一个 indexTTS2 语音生成服务搭建在局域网服务器上(需要使用高配显卡集群),这个服务不对公网提供访问,但我希望能在外网通过龙虾随时调用它。
但 nanobot 默认做不到。
无论是 web_fetch,还是 exec 里的 curl,只要目标是局域网地址(例如 192.168.x.x、10.x.x.x),都会被它的安全策略拦下来。
这其实不是什么 bug,而是一个很标准的 SSRF / 私网 访问防护设计。默认拒绝私网地址,这件事本身是对的。
问题在于,我的需求也是真的。
所以这篇文章要解决的,不是「如何粗暴地关掉 nanobot 的安全机制」,而是另一个问题:
如何在保留默认安全边界的前提下,让 nanobot 有控制地访问局域网资源。
我的最终方案是做一个基于白名单的私网访问策略:
- 默认仍然拒绝私网访问;
- 只有命中指定的 CIDR 或 Host 才允许放行;
- 改动尽量小,方便后续维护;
- 同时覆盖
web_fetch、exec和 subagent 的工具链路。
这件事说起来不复杂,真做起来,坑还不少。
尤其是在 Windows 服务部署环境下,很多问题并不是改完代码就结束了。
下面我从问题定位、方案设计、代码实现和部署验证四个方面,完整记录一下这次改造过程。
1. nanobot 为什么默认不能访问局域网
先说结论:nanobot 不能访问局域网,并不是某一个工具单独做了限制,而是平台层面做了多层防护。
我这次排查时,主要看到三个关键位置:
nanobot/security/network.pynanobot/agent/tools/web.pynanobot/agent/tools/shell.py
其中 network.py 是核心。它会识别常见的私有地址范围,例如:
10.0.0.0/8127.0.0.0/8172.16.0.0/12192.168.0.0/16
以及 localhost、link-local 和部分 IPv6 范围。
也就是说,只要 URL 目标落在这些地址范围里,就会被当作潜在的内部网络访问目标处理。
web_fetch 在真正请求 URL 之前会做一次安全校验。
exec 也不例外,它会直接检查命令字符串里是否包含私网 URL。
所以你看到的表象虽然是「agent 不能抓某个网页」,但本质上其实是平台级网络安全策略在生效。
2. 我的目标不是关闭安全
碰到这种需求,最简单的做法当然是:
- 注释掉私网检测;
- 或者把「检测到私网就报错」的逻辑改成直接放行。
这么看似既快又危险,实际上一点儿也不安全。
如果一个 agent 平台默认允许访问内网资源,那它的安全边界就会立刻变得非常模糊。
尤其是带有 web_fetch、exec、subagent 这类能力的时候,一旦把私网访问彻底放开,平台就有了探测和操作内网服务的潜力。例如局域网上或者本机有另一个 OpenClaw 进程在运行,那就能直接操作它的工作台。
所以我这次的目标从一开始就很明确:
不是全开,而是白名单放行。
换句话说:
- 默认行为不能变,还是拦;
- 用户必须显式配置,才允许访问特定内网目标;
- 白名单最好同时支持网段和主机名;
- 代码改动尽量收敛,不搞大重构。
很多时候,技术实现不是最难的。
如何以最小的改动,把正确的事情做进去,才是难点。
3. 白名单方案
既然目标是「默认拦截 + 显式放行」,那配置就应该足够直白。
我最后采用的配置结构是:
1{
2 "tools": {
3 "networkSecurity": {
4 "allowPrivateNetwork": false,
5 "allowedPrivateCidrs": ["192.168.31.0/24"],
6 "allowedPrivateHosts": []
7 }
8 }
9}
它的语义很简单:
allowPrivateNetwork:是否启用私网白名单能力;allowedPrivateCidrs:允许访问的私网网段;allowedPrivateHosts:允许访问的私网主机名。
例如:
1{
2 "tools": {
3 "networkSecurity": {
4 "allowPrivateNetwork": false,
5 "allowedPrivateCidrs": ["192.168.31.0/24"],
6 "allowedPrivateHosts": ["nas.local"]
7 }
8 }
9}
这样做的好处是,用户不需要理解 nanobot 的内部实现,也能一眼看懂这几个字段是做什么的。
我不太喜欢那种「为了显得优雅,把简单事情搞得很抽象」的配置设计。
一个配置项如果要靠半天文档才能看懂,那它多半就不算是一个好的配置项。
4. 代码实现改了哪些地方
这次最终改动涉及 7 个文件:
nanobot/security/network.pynanobot/config/schema.pynanobot/agent/tools/shell.pynanobot/agent/tools/web.pynanobot/agent/loop.pynanobot/agent/subagent.pynanobot/cli/commands.py
看起来文件不少,但职责其实很清楚:
schema.py定义配置结构;network.py统一处理私网判断和白名单放行;web.py负责web_fetch的 URL 校验与重定向校验;shell.py负责exec中私网 URL 的拦截与放行;cli/commands.py -> loop.py -> subagent.py负责把配置一路传进具体工具。
核心判断逻辑可以概括成这样:
1def _private_addr_allowed(addr, network_security_config) -> bool:
2 # addr 是私网地址时:
3 # 1. 判断当前是否启用私网白名单能力
4 # 2. 检查是否命中 allowedPrivateCidrs / allowedPrivateHosts
然后让下面这些入口统一走这套规则:
validate_url_target(...)validate_resolved_url(...)contains_internal_url(...)
这里有个很重要的点:
白名单判断应该尽量集中在 network 层,而不是散落在 web.py 和 shell.py 里各写一套。
否则:
- 你今天修了
web_fetch,明天漏了exec; - 今天 IPv4 正常,明天 Hostname 解析又不一致。
- 安全相关逻辑如果分散,后面一定会出问题。
5. 为什么我最后放弃了「三参数一路传递」
一开始我也想过最直接的办法:把三个参数平铺着一路往下传:
allow_private_networkallowed_private_cidrsallowed_private_hosts
这办法能不能用?能用。
但它会把很多函数签名都改脏。
- 原本一个函数参数很干净,现在突然多出三项;
- 原本只是构造一个 tool,现在又要同步这三项;
- 一路从
cli -> loop -> subagent -> tool -> network传下去,扩散面会很大。
所以我后来把它收敛成了单对象传递:统一传一个 network_security_config。
也就是说:
- CLI 把
config.tools.network_security传给AgentLoop AgentLoop再传给SubagentManagerExecTool和WebFetchTool都持有同一个配置对象- 到
network.py再从对象里读取allow_private_network、allowed_private_cidrs、allowed_private_hosts
调用链大致如下:
tools.networkSecurity] --> B[cli/commands.py] B --> C[AgentLoop] C --> D[SubagentManager] C --> E[WebFetchTool] C --> F[ExecTool] D --> G[Subagent WebFetchTool] D --> H[Subagent ExecTool] E --> I[security/network.py] F --> I G --> I H --> I
这里真正重要的不是「对象传递比较优雅」,而是:
维护成本高不高,不取决于它看起来扁平还是优雅,而取决于改动是不是集中、签名是不是扩散、冲突面是不是可控。
对这次补丁来说,单对象传递明显更克制,也更容易继续维护。
6. Windows 服务部署:Shawl、登录身份与路径问题
如果你以为代码改完就结束了,那就太乐观了。
我这里的 nanobot 跑在 Windows 上,而且是作为服务启动的。
我最终使用的是 Shawl,它是一个很好用的 Windows service wrapper for arbitrary commands,适合把普通命令包装成 Windows 服务来运行。
这类工具的好处很直接:
- 不需要自己写服务宿主程序;
- 可以把任意命令包装成服务;
- 支持重启、日志、超时等常见能力;
- 对命令行程序非常友好。
我这里就是用 Shawl 包装 nanobot gateway 来跑。
6.1 路径问题不是 nanobot 的 bug,而是登录身份不同
这个坑很典型。
手工在命令行里运行 nanobot gateway 的时候,一切正常。
但当它作为 Windows 服务启动后,却报了一些非常迷惑的问题,例如配置找不到、API Key 缺失之类。
最后排查下来,原因不是配置文件坏了,而是:
服务运行时使用的登录身份,与我平时手工登录 Windows 的身份不是同一个。
而在 Windows 下,不同登录身份对应的用户目录也不同。
这就导致服务进程解析出来的 ~/.nanobot 根本不是我平时使用的那个:
C:\Users\admin\.nanobot
而可能变成类似下面这种路径:
C:\Windows\System32\config\systemprofile\.nanobot
于是问题就出现了:
你明明已经在自己的用户目录下配好了 config.json,但服务进程根本没读到它。
所以这个问题的本质不是「路径错了」,而是运行服务的登录身份变了,用户主目录也跟着变了。
6.2 解决方法:显式指定配置路径
解决办法并不复杂:不要依赖 ~/.nanobot,而是显式指定配置文件路径。
例如:
1nanobot gateway --config C:\Users\admin\.nanobot\config.json
如果你用 Shawl 包装服务,就把这个参数直接写进服务命令行里。
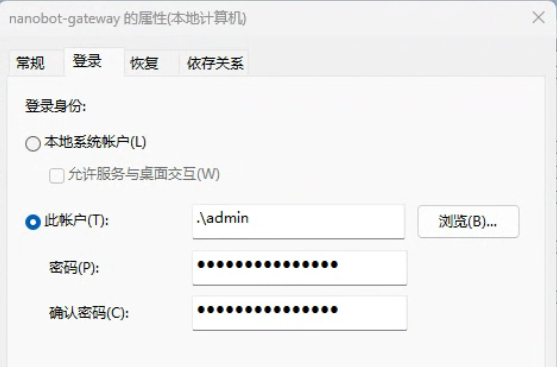
6.3 Windows 服务「登录身份」设置截图
看这个设置,比盯着报错日志瞎猜要有效得多。
6.4 本地源码安装不一定可靠,wheel 反而更稳
我这次还碰到另一个问题。
理论上,直接执行:
1uv tool install D:\storage\nanobot
看起来很方便。
但实际验证时发现,这种基于本地目录的安装方式,在某些情况下会让工具环境里残留旧包内容,导致你明明已经改了代码,运行结果却像没改一样。
最后验证下来,更稳的办法反而是:
- 先 build wheel;
- 卸载旧工具安装;
- 从新生成的 wheel 安装。
虽然步骤多一点,但结果更可控,也更容易确认「当前运行的到底是哪份代码」。
很多时候,工程上真正靠谱的方案,未必是最省命令的那个。
7. 最终验证
代码写完、服务跑起来之后,最重要的还是验证。
我的测试目标是一个局域网服务:
http://192.168.31.88:8888
配置中允许的网段是:
["192.168.31.0/24"]
也就是说,如果实现正确,那么这个地址应该可以通过白名单被访问。
7.1 web_fetch 验证通过
直接通过主工具链执行 web_fetch,成功获取到了页面内容。
目标站点返回了正常的 HTTP 200,并且内容提取也成功完成。
这里还有一个细节:
在抓取过程中,Jina Reader 对这个私网 URL 返回过 451 Unavailable For Legal Reasons,但工具随后正确回退到了本地可读性提取逻辑,最终依然拿到了页面正文。
这说明白名单放行不仅通过了前置校验,也在实际抓取链路里工作正常。
7.2 exec 验证通过
我还验证了下面这条命令:
curl http://192.168.31.88:8888
在原本的逻辑里,这类命令会因为包含私网 URL 被直接拦截。而在加入白名单策略之后,这条命令已经可以正常通过 guard 检查。
这一步很关键。
因为如果只修了 web_fetch,没有修 exec,那整个平台的 LAN 能力其实还是不完整的。
7.3 基础检查也通过了
除了实际访问测试,我还做了几项基础验证:
- 对修改过的文件执行
py_compile - 检查是否还残留旧的三参数调用方式
- 执行
git diff --check
这些验证虽然不花哨,但很必要。因为一个安全策略补丁,如果连最基本的静态检查都没过,那后面的「能跑通」其实说服力也有限。
8. 这次改造真正重要的,不是「能访问 LAN」
如果只是为了访问内网,我完全可以写一个外部脚本,或者单独做一个 LAN skill,然后绕过主工具链去抓数据。
但我最后还是选择改 nanobot 本体,是因为我更关心另一件事:
如何把一个真实需求,变成平台层面可维护、可配置、可验证的能力。
「能不能访问 LAN」只是表象。 真正重要的是下面这些事情有没有一起成立:
- 默认是否仍然安全;
- 放行是否足够精确;
- 实现是否覆盖完整工具链;
- 改动是否尽量小;
- 后续是否容易继续维护。
如果这些问题没有同时解决,那么「能访问 LAN」这件事本身其实没多大价值。
在 agent 时代,这类问题以后只会越来越多。
因为 agent 的能力边界越来越像「一个会看、会想、会执行命令的操作员」,而不是一个简单的 API 调用器。当能力变强之后,安全边界、配置边界和工程边界就都不能靠拍脑袋决定了。
9. 总结
这次给 nanobot 增加局域网访问能力,我最终采用的是一个白名单式私网访问方案:
- 默认仍然拒绝访问内网;
- 通过
tools.networkSecurity显式配置允许的 CIDR 和 Host; - 同时覆盖
web_fetch、exec和 subagent 工具链; - 在实现上采用
network_security_config单对象传递,减少签名扩散; - 在部署上通过 Shawl 包装 Windows 服务,并显式指定
--config保证配置路径稳定。
回头看,这次工作里最值得记录的,不是某一行代码怎么改,而是这几个判断:
- 不要为了满足需求,顺手破坏默认安全边界;
- 不要为了写得「优雅」,把一个小功能改成大手术;
- 不要以为代码能跑就算完成,部署环境和验证链路同样重要。
- 对于一个本地自用的 agent 来说,访问局域网资源是很自然的诉求。
- 但「自然的诉求」,并不意味着可以「随便地实现」。
技术方案真正成熟的标志,从来都不是它「终于能用了」,而是它在能用之外,还尽量保持了边界、克制和可维护性。
- 文章ID:2858
- 原文作者:zrong(Jacky)
- 原文链接:https://blog.zengrong.net/post/nanobot-lan-whitelist/
- 版权声明:本作品采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可,非商业转载请注明出处(原文作者,原文链接),商业转载请联系作者获得授权。